Large Language Models (LLMs) like GPT-4 have become a transformative technology, powering everything from chatbots to advanced data analysis. However, concerns about privacy, data security, and specific business needs often necessitate building a private LLM tailored to your requirements. In this article, we’ll explore how to build a private LLM, ensuring it meets your unique needs while maintaining control over your data.
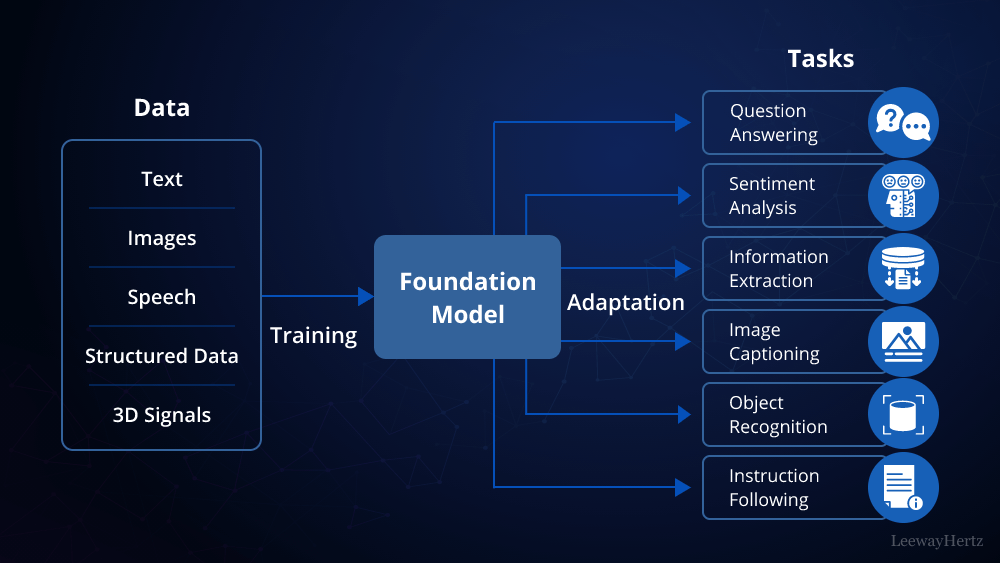
Why Build a Private LLM?
Building a private LLM allows organizations to have complete control over their data, ensuring that sensitive information is not exposed to third-party services. It also enables customization of the model to better suit specific use cases, industries, or business goals. Whether you’re in healthcare, finance, or any other sector with stringent data privacy requirements, a private LLM can offer a robust solution.
Step 1: Define Your Requirements
Before diving into the technical aspects of how to build a private LLM, it’s crucial to clearly define your requirements. Consider the following:
- Purpose and Use Case: Identify what you want your private LLM to achieve. Is it for customer support, content generation, data analysis, or something else?
- Data Privacy and Compliance: Understand the legal and regulatory requirements relevant to your industry, such as GDPR, HIPAA, or CCPA.
- Scalability and Performance: Determine the scale at which your LLM needs to operate. Will it serve a small team, or will it need to handle thousands of queries per day?
Having a clear understanding of these factors will guide your decisions throughout the process.
Step 2: Choose the Right Model Architecture
The next step in how to build a private LLM is selecting the appropriate model architecture. Popular architectures include GPT, BERT, and T5, each with its strengths:
- GPT (Generative Pre-trained Transformer): Ideal for generating text and conversational AI.
- BERT (Bidirectional Encoder Representations from Transformers): Best suited for understanding context and meaning in text.
- T5 (Text-To-Text Transfer Transformer): Great for tasks that can be framed as text-to-text problems, like translation or summarization.
Selecting the right architecture depends on your use case. For instance, if your goal is to create a conversational agent, GPT might be the best fit. On the other hand, for tasks requiring deep understanding of text, BERT could be more appropriate.
Step 3: Gather and Prepare Your Data
Data is the backbone of any LLM. To build a private LLM, you’ll need a large, high-quality dataset relevant to your domain. Here’s how you can approach this:
- Collect Data: Gather text data from various sources such as company documents, customer interactions, or publicly available data that aligns with your needs.
- Clean and Preprocess Data: Remove any irrelevant information, clean up the text, and structure it in a way that is suitable for training your model. This may include tokenization, normalization, and removing duplicates.
The quality and relevance of your data directly impact the performance of your private LLM, so invest time in this step.
Step 4: Train the Model
Training an LLM requires significant computational resources. Here’s a simplified approach to training your private LLM:
- Choose Your Infrastructure: You can use cloud services like AWS, Google Cloud, or Azure, which offer powerful GPUs and TPUs suitable for training large models. Alternatively, if privacy is a top concern, consider on-premises hardware.
- Fine-Tune the Model: Start with a pre-trained model that closely matches your needs and fine-tune it on your specific dataset. This approach, known as transfer learning, significantly reduces the resources and time required compared to training from scratch.
During training, monitor performance metrics like loss and accuracy to ensure your model is learning effectively.
Step 5: Evaluate and Optimize
Once your model is trained, it’s essential to evaluate its performance to ensure it meets your expectations:
- Testing: Use a separate dataset to test your private LLM’s performance. Check how well it generalizes to new, unseen data.
- Optimize: Based on your evaluation, tweak parameters, adjust the training data, or refine the model architecture to improve performance.
Continuous iteration and improvement are key to developing a robust private LLM.
Step 6: Deploy and Monitor
After building and fine-tuning your private LLM, the final step is deployment:
- Deploy: Use a suitable deployment framework that supports your environment, such as TensorFlow Serving, ONNX Runtime, or custom solutions for on-premises deployments.
- Monitor Performance: Continuously monitor the model’s performance in production, looking out for issues like drift in model accuracy over time or changes in data patterns.
Regular monitoring and updates will ensure that your private LLM continues to meet your needs as they evolve.
Conclusion
Building a private LLM offers numerous benefits, including enhanced data privacy, customization, and control. By following these steps on how to build a private LLM—defining requirements, selecting the right architecture, gathering and preparing data, training, evaluating, and deploying—you can create a model that meets your specific needs. With careful planning and the right resources, building a private LLM can be a powerful way to leverage advanced AI capabilities while maintaining control over your data.
By understanding the fundamentals of how to build a private LLM, you are well-equipped to embark on this journey, making advanced AI accessible and secure for your organization.

Leave a comment