Introduction
In the rapidly evolving field of artificial intelligence (AI), multimodal models have emerged as a powerful tool for integrating and processing diverse types of data. By combining various data sources, these models enhance the ability of AI systems to understand and generate more accurate and meaningful outputs. This article delves into what multimodal models are, how they work, their applications, and the challenges they face, offering insights into their significant role in advancing AI.
What Are Multimodal Models?
Multimodal models refer to AI systems that can process and analyze multiple types of data simultaneously. These data types, or modalities, include text, images, audio, video, and even sensor data. The goal of multimodal models is to leverage the strengths of different data modalities to produce more accurate, comprehensive, and context-aware outputs.
For instance, a multimodal model might combine textual descriptions with images to better understand and generate content. This capability allows AI to go beyond the limitations of single-modal models, which rely on one type of data at a time. By integrating multiple modalities, multimodal models can achieve a deeper understanding of context and nuances, leading to more effective AI applications.
How Multimodal Models Work
At the core of multimodal models is the ability to merge and process data from different modalities. This process involves several key steps:
- Data Representation: Each modality is represented in a way that the model can process. For example, text might be represented as word embeddings, while images might be represented as pixel matrices or feature vectors.
- Fusion Techniques: The data from different modalities is then fused or combined. There are various techniques for this, such as early fusion, where data is combined at the input level, and late fusion, where data is combined at the decision-making stage. Some models use hybrid approaches, combining elements of both early and late fusion.
- Modeling and Learning: The multimodal data is fed into a model, which could be a neural network or another type of AI model. The model learns to recognize patterns and relationships across the different modalities, allowing it to make more informed predictions or generate outputs.
- Output Generation: Finally, the model produces an output, which could be a classification, a generated image, a piece of text, or any other type of AI-generated content. The output is typically more robust and accurate due to the integration of multiple data sources.
Applications of Multimodal Models
The versatility of multimodal models makes them applicable across a wide range of industries and tasks. Some of the most prominent applications include:
- Natural Language Processing (NLP) and Computer Vision Integration: In applications like image captioning, multimodal models combine image analysis with natural language processing to generate descriptive captions for images. This capability is crucial in fields like content creation, accessibility technology, and social media.
- Healthcare: Multimodal models are used in healthcare to integrate data from medical images, patient records, and sensor data to improve diagnostics and treatment planning. For example, combining MRI scans with patient histories can lead to more accurate diagnoses.
- Autonomous Vehicles: Autonomous vehicles rely on multimodal models to process data from cameras, LiDAR, radar, and other sensors. By integrating these data sources, vehicles can better understand their environment and make safer driving decisions.
- Human-Computer Interaction: In virtual assistants and other interactive systems, multimodal models allow for more natural and effective communication by integrating speech, text, and visual cues.
- Multimedia Search Engines: Multimodal models enhance search engines by enabling them to understand and index multimedia content more effectively. This allows users to search for content using a combination of text and images, improving search accuracy and relevance.
Challenges and Future Directions
Despite their potential, multimodal models face several challenges that need to be addressed to fully realize their capabilities:
- Data Alignment: One of the biggest challenges is ensuring that data from different modalities are aligned correctly. Misalignment can lead to errors in the model’s understanding and output.
- Complexity and Computation: Multimodal models are often more complex and computationally intensive than single-modal models. This complexity can make them difficult to train and deploy, particularly in resource-constrained environments.
- Interpretability: As multimodal models become more complex, understanding how they arrive at specific decisions becomes more challenging. Improving the interpretability of these models is crucial for building trust and ensuring their ethical use.
- Data Availability and Quality: High-quality data from multiple modalities is essential for training effective multimodal models. However, obtaining such data can be difficult, particularly in fields like healthcare where data is sensitive and regulated.
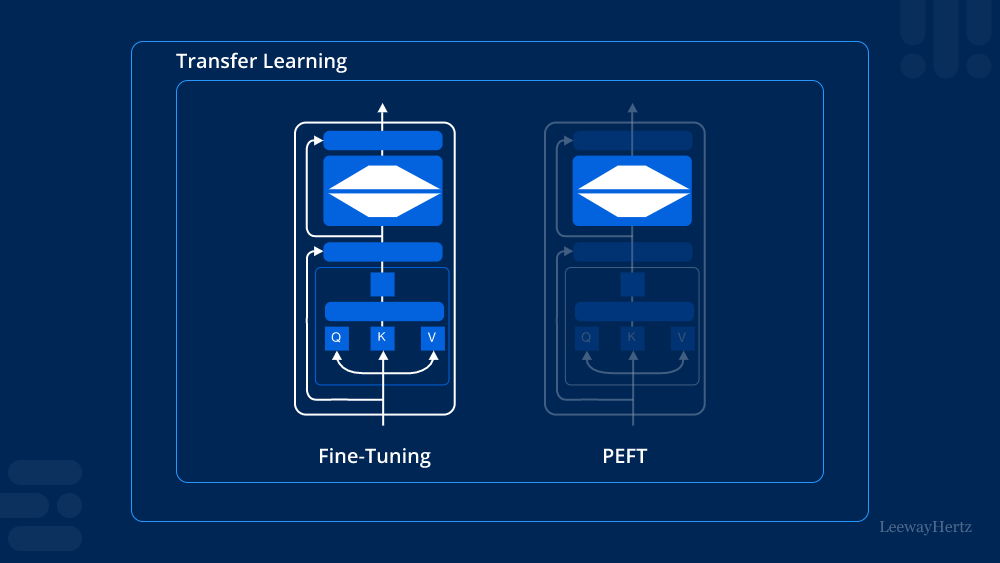
Looking ahead, research and development in multimodal models are likely to focus on improving their efficiency, interpretability, and real-world applicability. Advances in areas like transfer learning, where models trained on one task are adapted to another, and self-supervised learning, where models learn from unlabelled data, are expected to play a key role in overcoming current challenges.
Conclusion
Multimodal models represent a significant advancement in the field of AI, offering the ability to process and integrate diverse types of data for more accurate and meaningful outputs. As these models continue to evolve, they hold the potential to revolutionize various industries, from healthcare and autonomous vehicles to human-computer interaction and multimedia search. However, addressing the challenges associated with data alignment, complexity, and interpretability will be crucial for the successful deployment of multimodal models in real-world applications.

Leave a comment