Multimodal models are transforming the way artificial intelligence (AI) systems process and interpret data. These models integrate different types of data, such as text, images, and audio, to create more intelligent and adaptable AI systems. As technology evolves, multimodal models are gaining more attention due to their ability to enhance machine learning applications, improve decision-making processes, and generate more accurate results. In this article, we’ll dive deep into the concept of multimodal models, their applications, and how they’re shaping the future of AI.\
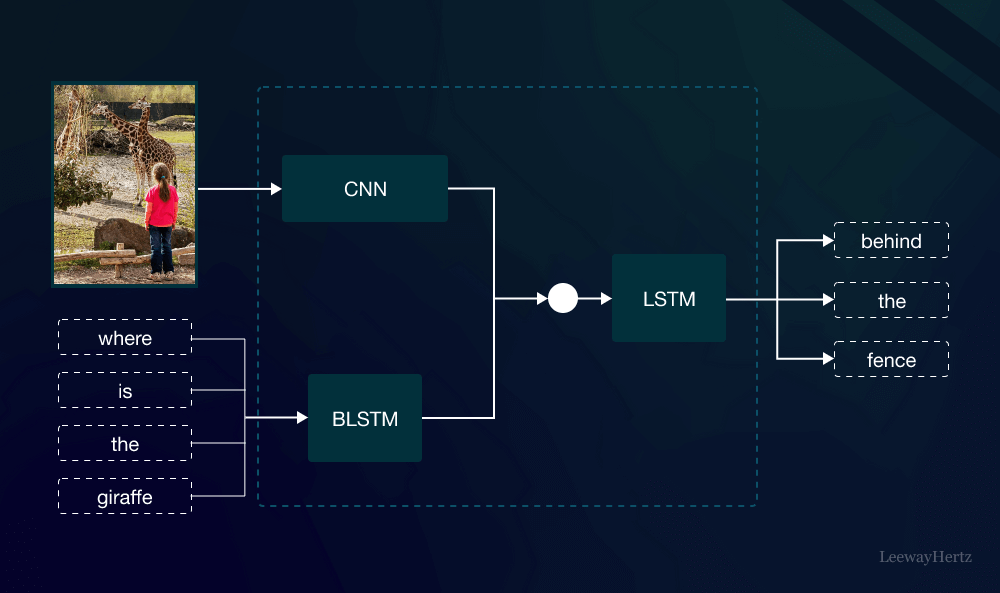
What Are Multimodal Models?
Multimodal models are AI systems that can process multiple types of data simultaneously. Traditionally, AI models were designed to handle only one type of data input, such as text or images. However, with the advent of more advanced techniques, multimodal models can integrate different kinds of inputs, such as text, images, and audio, and analyze them in combination. This allows these models to understand complex scenarios better and generate more meaningful outputs.
For example, a multimodal model could take an image of a car and a description of that car and combine these inputs to better understand the vehicle’s characteristics. In contrast, traditional models would only rely on either the image or the text alone, missing out on the broader context provided by multiple sources of information.
The Importance of Multimodal Models in AI
The growing importance of multimodal models lies in their ability to enhance machine learning applications. They make it possible for AI systems to better interpret the world by processing information in ways that are closer to human understanding. Humans naturally combine multiple senses to make decisions—such as using sight and sound to navigate their environment. Similarly, multimodal models give AI the ability to process multiple streams of data, leading to more accurate, flexible, and insightful outcomes.
By combining various data modalities, these models provide richer information and help AI applications operate in real-world environments where data is often complex and varied. Whether it’s in healthcare, autonomous vehicles, or virtual assistants, multimodal models are essential for creating AI systems that can operate efficiently in diverse settings.
Key Components of Multimodal Models
To better understand how multimodal models work, it’s important to break down their core components. These include:
1. Data Fusion
Data fusion refers to the process of integrating multiple types of data into a single, cohesive model. This can be done at different levels—early fusion, where data is combined at the input stage; intermediate fusion, where different types of data are processed separately before being merged; and late fusion, where individual results are combined at the final stage of processing.
2. Feature Extraction
Feature extraction is the process of identifying important aspects or characteristics of data that will be used by the multimodal model. For example, in image recognition, the model might extract features like shapes or colors, while in natural language processing (NLP), it would extract relevant words or phrases. When these features are extracted from different data types, the model can learn patterns that might be missed if only a single data type was considered.
3. Multimodal Learning
Multimodal learning is the technique through which AI systems learn to interpret and combine information from different data sources. The goal is to improve the model’s performance by utilizing the strengths of each data type. For instance, combining text and image data can enhance a model’s understanding of a concept by providing more context and clarity.
Applications of Multimodal Models
The applications of multimodal models are diverse and expanding across various industries. Here are some of the key sectors benefiting from these AI systems:
1. Healthcare
In healthcare, multimodal models are used to combine patient records, medical images, and lab results to provide a more comprehensive understanding of a patient’s condition. This allows for more accurate diagnoses and personalized treatment plans. For example, a multimodal model can analyze MRI scans alongside patient symptoms and genetic data to identify early signs of diseases more effectively.
2. Autonomous Vehicles
Autonomous vehicles rely heavily on multimodal models to process various types of sensory input, including images from cameras, signals from radar, and even audio data. By combining these data sources, multimodal models help self-driving cars make better decisions in real-time, ensuring safer navigation through complex environments.
3. Natural Language Processing
In the field of natural language processing, multimodal models are used to enhance the understanding of human communication. By integrating text, speech, and even gestures, these models can improve the performance of virtual assistants, chatbots, and language translation services, making them more intuitive and responsive.
4. Entertainment and Media
Multimodal models are also making waves in the entertainment industry. For example, these models are used in video games to combine visual effects, soundtracks, and character dialogues to create more immersive experiences. They also play a key role in content recommendation systems by analyzing users’ preferences across multiple types of media, such as videos, articles, and music, to offer more personalized suggestions.
Challenges in Developing Multimodal Models
While multimodal models offer immense potential, they also present certain challenges. Developing these models requires sophisticated techniques and large amounts of diverse data. One of the main hurdles is ensuring that the data from different modalities is properly synchronized and aligned. For example, an AI model that processes video and audio data must ensure that both streams are in sync, which can be technically complex.
Another challenge is the computational resources required to train multimodal models. Since these models process several types of data simultaneously, they demand more processing power and storage capacity than single-modal models. This can make them more expensive and difficult to implement, particularly for smaller organizations.
The Future of Multimodal Models
As AI continues to evolve, the role of multimodal models will become even more prominent. Future developments in this field could lead to more intuitive and intelligent systems capable of understanding the world as humans do. For instance, multimodal models could be used to build AI systems that can interpret complex scenarios in real-time, such as analyzing security footage, reading textual reports, and listening to audio signals simultaneously to detect potential threats.
In addition, advancements in multimodal learning could result in more efficient AI systems that require less data to achieve high performance. This would make multimodal models more accessible to industries that may not have access to large datasets or advanced computational infrastructure.
Conclusion
Multimodal models represent a significant leap forward in the development of AI systems. By integrating multiple types of data, these models enable AI to process information in ways that more closely mimic human cognition, leading to better decision-making and more robust outcomes. From healthcare and autonomous vehicles to entertainment and natural language processing, the applications of multimodal models are vast and rapidly growing. As AI technology continues to advance, multimodal models will undoubtedly play a key role in shaping the future of intelligent systems.

Leave a comment